I was always interested in technology stack of large-scale startups. It’s quite interesting to follow the evolutions of the company during not so long periods. From one point, it’s interesting to follow changes of technologies, but much more interesting are reasons which have led to such decisions. So today I’m going to share the story of Linkedin told by Jay Kreps, Principle Staff Engineer at LinkedIn during the InfoQ conference.
Jay describes the evolution of the startup’s architecture from the simplest iteration
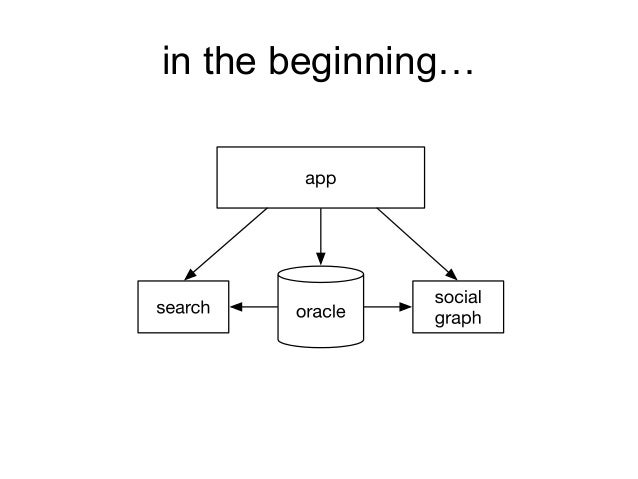
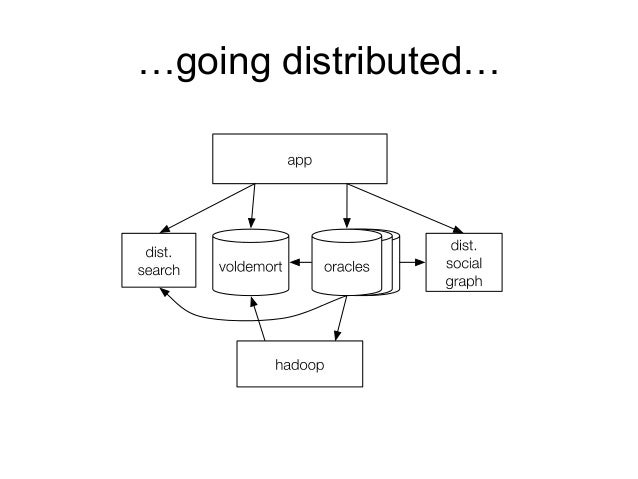
to more distributed with more elements like voldemort and hadoop
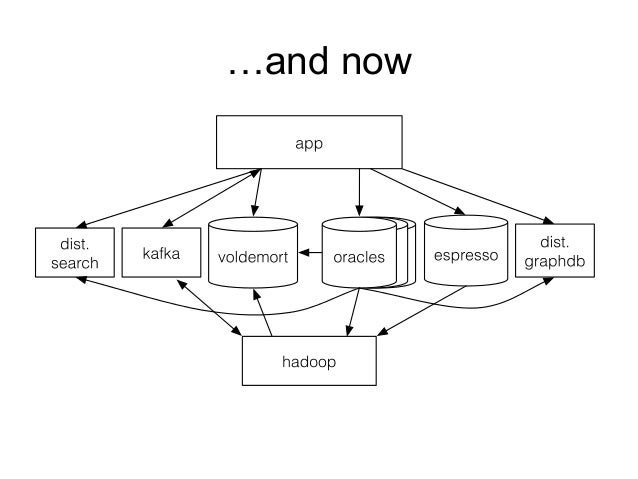
and even more with Apache Kafka, messaging system, and Espresso, key-value database.
The main idea Jay tells us, is to try to use simple, cheap and scalable primitives to be able to re-use
one infrastructure for different purposes. Another idea is to have all expensive operation asynchronously,
because all, that could fail, is going to fail and all front-end would follow the failing backend.
Hard things should be executed offline, because they are safe and cheap, while offline.
Another big line of the presentation is transition from monolithic application architecture to service oriented architecture.
The big idea reminds me of the principle of The Twelve-Factor App
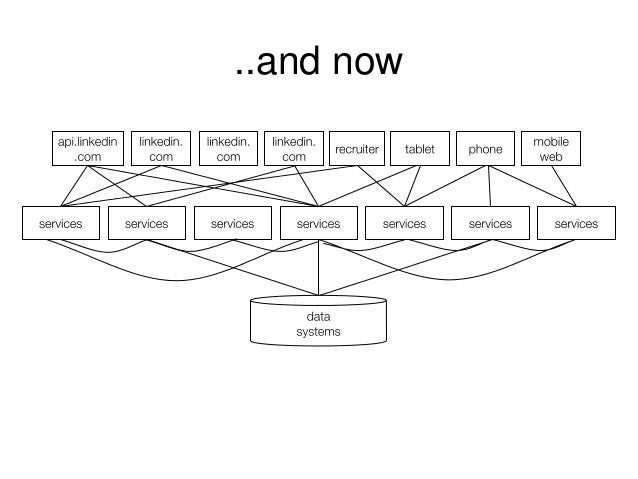
The main advantage of such methodology is ability to easily iterate over versions, to be quite independent inside the service and
to re-use some primitives of the infrastructure. By the way, deciding to move forward with
software-as-a-service methodology, we need to understand the problem of the granularity of a service. Also about among-server communication,
within Linkedin they changed a couple of integration layers started from HTTP + serializable Java, after Protocol Buffer + TCP and finally REST + JSON.
There is also a good explanation of the idea to have a code owner and treating the code as property. Discussed main points of interaction within team and other aspects of agile at scale.
The full version of the video could be found by link
Another post about large-scale architecture of startups: Scaling Pinterest